单调栈
单调栈的用途不太广泛,只处理一种典型的问题,叫做 Next Greater Element。
单调栈模版
给你一个数组nums,请你返回一个等长的结果数组,结果数组中对应索引存储着下一个更大元素,如果没有更大元素,就存
-1。
例如:输入一个数组
nums = [2,1,2,4,3],你返回数组[4,2,4,-1,-1]
ps: 第⼀个 2 后⾯⽐ 2 ⼤的数是 4; 1 后⾯⽐ 1 ⼤的数是 2;第⼆个 2 后⾯⽐ 2 ⼤的数是 4; 4 后⾯没有⽐ 4⼤的数,填 -1;3 后⾯没有⽐ 3 ⼤的数,填 -1。
当然我们很轻松就可以想到暴力解法,就是对每个元素后面都进行遍历,找到第一个更大的元素就可以了,但是暴力解法的时间复杂度是O(n^2)
这个问题可以这样抽象思考:把数组的元素想象成并列站⽴的⼈,元素⼤⼩想象成⼈的身⾼。这些⼈⾯对你站成一列,如何求元素「2」的Next Greater Number呢?
很简单我们只需要把它能看到的一个元素就是答案,因为矮的都被挡着看不到。
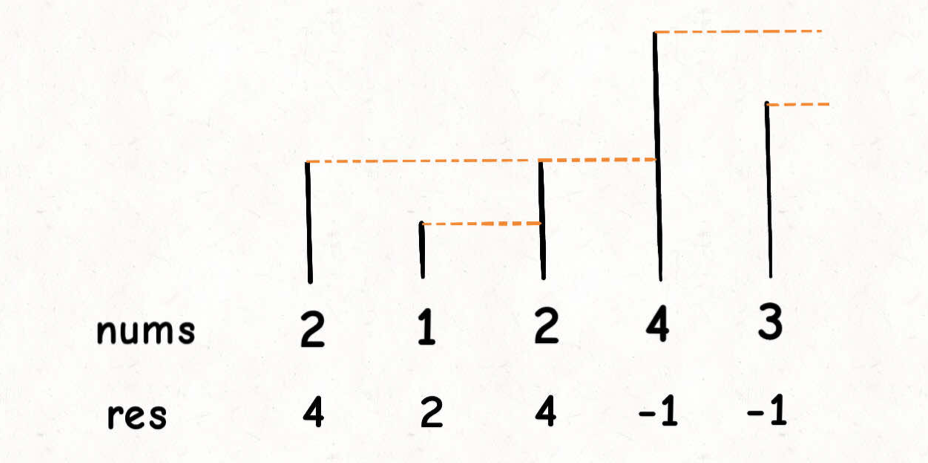
我们从后面开始看,3 前面没人,所有输入 -1,4前面没有比它大的,并且3 比它小,所以把 3 出栈,并输入 -1 ,2 前面有 4 比它大,所以输入4,并且2入栈,1 前面第一个看到的是 2, 所以输入 2, 并且进栈,2 前面看到的是 4 ,输入4 并且前面的1 和 2 都出栈。
最后逆序输出即可,这就是为什么需要到栈,下面就是代码:
1 | vector<int> nextGreaterElement(vector<int>& nums){ |
时间复杂度为O(N),因为每个元素最多进栈一次。
496. 下一个更大元素 I
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。
对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。
返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素 。
示例:
输入:nums1 = [4,1,2], nums2 = [1,3,4,2].
输出:[-1,3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
4 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
1 ,用加粗斜体标识,nums2 = [1,3,4,2]。下一个更大元素是 3 。
2 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
思路:
和前面我们介绍的模版一样,这里只是我们需要用到哈希表,先存储num2 中的下一个更大元素,最后在根据哈希表查找num1中对应的值。
1 | class Solution { |
739. 每日温度
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指在第 i 天之后,才会有更高的温度。如果气温在这之后都不会升高,请在该位置用 0 来代替。
示例:
输入: temperatures = [73,74,75,71,69,72,76,73]
输出: [1,1,4,2,1,1,0,0]
思路:
和前面不同的是,现在求的是下一个更大元素的距离,我们现在入栈的不能是元素的值,而是元素的下标。我们用栈顶元素的下标减去当前元素的下标,不就是要求的距离吗?
1 | class Solution { |
如何处理循环数组
比如输入一个循环数组[2,1,2,4,3]你返回[4,2,4,-1,4],最后一个元素3绕了一圈后找到了比自己大的元素4.
我们可以把原来的循环数组复制一份,变成[2,1,2,4,3,2,1,2,4,3],这样我们就可以用前面说过的模版来解决了,当然我们也不是一定需要真的复制一份数组,可以采用%求模运算,来实现。
503. 下一个更大元素 II
给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是 nums[0] ),返回 nums 中每个元素的 下一个更大元素 。
数字 x 的 下一个更大的元素 是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1 。
示例:
输入: nums = [1,2,1]
输出: [2,-1,2]
解释: 第一个 1 的下一个更大的数是 2;
数字 2 找不到下一个更大的数;
第二个 1 的下一个最大的数需要循环搜索,结果也是 2。
思路:
前面分析的一样,通过将数组翻倍来解决。
1 | class Solution { |
数组去重
316. 去除重复字母
给你一个字符串 s
,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证
返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
示例:
输入:s = "bcabc"
输出:"abc"
思路:
对于一般的去重,我们只需要借助哈希表就可以解决了,但是现在却要我们保持字典序最小。
题目要求:
- 去重
- 去重后不能打乱 s 中字符出现的相对顺序
- 在所有符合上条的去重字符串中,字典序最小
按理说,如果我们想要得出有序的结果,那必然要排序,可是排序后相对位置就不能保证,这似乎有点矛盾。
我们可以借用前面讲的单调栈来实现。
首先我们先不用考虑第三个条件,我们可以写出这样的代码
1 | string removeDuplicateLetters(string s) { |
这样,例如s = "babc",我们就得到了bac,但是答案却是abc,因为它的字典序更小。如果我们要满足条件三,保证字典序,我们需要做什么呢?
就比如到a的时候,我们发现栈中b的字典序比它小,并且后面还有出现,我们可以把b弹出。这关键是我们怎么知道后面b会不会出现呢,我们只需要前期用一个数组,统计s中每个字符出现的次数,当它是唯一一个时,就不在被弹出,否则弹出。
1 | class Solution { |